Les structures de données
Sommaire
Jusqu’à présent, nous ne pouvions manipuler que des variables dont le type était l’un des types de base du langage C. Il s’agit d’une restriction assez forte. Beaucoup trop forte même si l’on souhaite réaliser une application commerciale ou tout autre projet d’envergure. En effet, lorsque l’on réalise un programme, il est nécessaire de passer par une phase dite de modélisation. Cette phase de modélisation est cruciale car elle permet de décrire les objets que nous allons manipuler. Par exemple, si nous souhaitons réaliser un répertoire téléphonique (application classique réalisée lors des séances de travaux dirigés…), il est naturel de vouloir manipuler des contacts, regroupant l’ensemble des informations concernant un individu (par exemple son age, son nom, son prénom, son adresse etc…) plutôt qu’un ensemble de variables ou de tableaux de variables pour enregistrer toutes ces informations. Imaginez un peu si on devait conserver l’âge d’un millier de contacts avec des variables ! Et même si on utilise des tableaux, imaginez si on enregistre une centaines d’informations sur chaque contact… Cela ferait une centaine de tableaux à manipuler ! C’est bien trop lourd, trop pénible et trop rébarbatif ! Il est bien plus pratique et naturel de manipuler des données qui correspondent à ce que l’on manipule.
Le langage C permet de définir des nouveaux types de données (que l’on dit structurés, composés) via les structures. C’est grâce à ce mécanismes que nous pourrons manipuler des variables qui correspondent à la réalité.
Définir une structure, un nouveau type de données

Voici comment déclarer une structure :
|
1 2 3 4 5 6 7 8 |
struct nomDeLaStructure { typeDuChamp_1 nomDuChamp_1; typeDuChamp_2 nomDuChamp_2; typeDuChamp_3 nomDuChamp_3; typeDuChamp_4 nomDuChamp_4; ... }; |
Attention : la dernière accolade doit être suivie d’un point-virgule ! Cette définition doit se faire juste après les directives du pré-processeur, c’est-à-dire après les #include et les #define. En fait, vous pouvez définir une structure n’importe où dans votre code du moment que vous n’êtes pas dans une fonction mais encore une fois, si vous souhaitez réaliser un code propre, c’est-à-dire facilement lisible par vos collègues, vous devez respecter certaines conventions.
- Le nom des champs respecte les critères des noms de variable
- Deux champs d’une même structure ne peuvent avoir le même nom
- Les champs peuvent être de n’importe quel type hormis le type de la structure dans laquelle elles se trouvent
Une petite remarque (que vous pouvez ignorer pour le moment) concernant le dernier point : un champs ne peut pas être du même type que la structure mais il peut être du type pointeur vers cette structure. C’est cette particularité qui autorise les listes chaînées, mais nous y reviendrons plus tard, durant le cours sur les listes chaînées justement.
Un petit exemple de structure permettant de manipuler des points en trois dimensions, avec trois coordonnées x, y et z (très utile si vous voulez réaliser un petit moteur 3D) :
|
1 2 3 4 5 6 |
struct point { float x; float y; float z; }; |
Facile non ? Mais maintenant, comment déclarer une variable de ce type nouvellement défini ? Et surtout, comment manipuler une variable de ce type puisqu’elle contient plusieurs champs ?
Pour déclarer une variable, il suffit de faire comme pour les types de base, en donnant tout d’abord le nom du type puis le nom de la variable. Attention toutefois car le nom du nouveau type sera précédé par le mot clé struct :
|
1 |
struct nomDeLaStructure nomDeLaVariable; |
Dans notre exemple, cela donne :
|
1 |
struct point monpoint; |
Ensuite on peut manipuler cette variable comme n’importe quelle autre variable. Reste encore le problème de l’accès aux différents champs de la variable. En fait, c’est vraiment très simple, puisqu’il suffit de faire suivre le nom de la variable par un point puis le nom du champs concerné. On peut ensuite manipuler ce champs comme n’importe quelle variable. Exemple :
|
1 2 3 |
monpoint.x=5.0; monpoint.y=1.0; monpoint.z=12.0; |
Allez, un exemple complet :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
#include<stdio.h> #include<stdlib.h> struct point { float x; float y; float z; }; int main (void) { struct point monpoint; monpoint.x=5.0; monpoint.y=1.0; monpoint.z=12.0; printf("les coordonnées du point sont :(%f,%f,%f)\n",monpoint.x, monpoint.y, monpoint.z); return 0; } |
initialisation lors de la déclaration
Nous avons vu dans le cours sur les variables qu’il est préférable d’initialiser les variables lors de leur déclaration. Cette règle s’applique également aux variables structurées. Voici comment procéder, en reprenant notre petit exemple :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
#include<stdio.h> #include<stdlib.h> struct point { float x; float y; float z; }; int main (void) { struct point monpoint={5.0,1.0,12.0}; printf("les coordonnées du point sont :(%f,%f,%f)\n",monpoint.x, monpoint.y, monpoint.z); return 0; } |
Les tableaux de structures
Étant donné que nous venons de définir un nouveau type de données, nous pouvons le manipuler comme n’importe quel autre type. Ainsi, nous pouvons également définir des tableaux de ce type. La manipulation de ces tableaux n’est pas différente des tableaux dont le type est un type de base. Et comme il n’y a rien de mieux qu’un bon exemple :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
#include<stdio.h> #include<stdlib.h> struct point { float x; float y; float z; }; int main (void) { int i; struct point tab[10]; for(i=0;i<10;i++) { tab[i].x=1.5*i; tab[i].y=2.0*i; tab[i].z=5.0; } for(i=0;i<10;i++) { printf("les coordonnées du point sont :(%f,%f,%f)\n", tab[i].x, tab[i].y, tab[i].z); } return 0; } |
Simplifier le nom du type nouvellement créé
Les développeurs sont fainéant. C’est un fait. Et écrire le mot struct à chaque fois que l’on souhaite déclarer une variable structurée est typiquement le genre de choses que les codeurs détestent :
|
1 |
struct point monpoint; |
En effet, ce que nous souhaitons en définissant cette structure, c’est définir un nouveau type de données appelé point. Grâce au mot clé typedef, il est possible de créer un alias au nom struct point :
|
1 |
typedef struct point unNouveauNom; |
Désormais, on peut utiliser unNouveauNom de la même manière que struct point :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
#include<stdio.h> #include<stdlib.h> struct point { float x; float y; float z; }; typedef struct point unNouveauNom; int main (void) { struct point monpoint={5.0,1.0,12.0}; unNouveauNom p2={6.0,7.0,8.0}; printf("\nles coordonnées du point monpoint sont :(%f,%f,%f)\n",monpoint.x, monpoint.y, monpoint.z); printf("\nles coordonnées du point p2 sont :(%f,%f,%f)\n",p2.x,p2.y,p2.z); return 0; } |
Les pointeurs et les structures
Nous abordons maintenant un point qui a tendance à perturber les étudiants lorsqu’ils ne sont pas parfaitement attentifs… Pour comprendre cette partie vous devez savoir manipuler les pointeurs. Si ce n’est pas le cas, ce n’est pas trop tard : le cours sur les pointeurs.
Nous venons de définir un nouveau type de données que nous pouvons manipuler comme bon nous semble. En particulier, nous pouvons définir des pointeurs de ce type. Exemple :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
#include<stdio.h> #include<stdlib.h> struct fract { int a;//pour le numérateur int b;//pour le dénominateur }; typedef struct fract fraction; int main (void) { fraction f1={2,3}; fraction f2={1,2}; fraction *pt=NULL; pt =&f1; return 0; } |
Dans cet exemple, nous définissons un nouveau type nommé fraction qui va nous permettre de manipuler…des fractions. Le champs a permettant d’enregistrer le numérateur tandis que le champs b va nous permettre de manipuler le dénominateur. Nous déclarons deux variables de type fraction, à savoir f1 et f2, que nous initialisons lors de la déclaration. Ensuite, nous déclarons un pointeur nommé pt vers une variable de type fraction que nous initialisons à NULL. Ensuite, nous faisons pointer ce pointeur vers f1, ce qui revient à dire que pt contient l’adresse de la variable f1.
Maintenant, si nous voulons accéder au contenu de la variable pointée par pt, comment devons nous faire ? Nous avons vu dans le cours sur les pointeurs que pour acceder au contenu d’une variable à partir d’un pointeur, nous devons utiliser l’opérateur *.
Maintenant, réfléchissons un petit instant. Si nous appliquons l’opérateur * sur notre pointeur pt, à quoi avons nous accès ? Nous avons accès au contenu de la variable f1. Si nous voulons manipuler ce contenu, nous devons le faire champs par champs.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
#include<stdio.h> #include<stdlib.h> struct fract { int a;//pour le numérateur int b;//pour le dénominateur }; typedef struct fract fraction; int main (void) { fraction f1={2,3}; fraction f2={1,2}; fraction *pt=NULL; pt =&f1; printf("Voici la fraction f1 : %d/%d",f1.a,f1.b); (*pt).a=9; (*pt).b=(*pt).a; printf("\nVoici la fraction f1 : %d/%d",f1.a,f1.b); return 0; } |
Lorsque vous serez amené à réaliser un projet important, vous vous rendrez compte que ce genre de notation, bien que très clair, est assez rébarbative. Aussi, il existe une autre syntaxe qui permet de manipuler le contenu des champs d’une variable pointée. Plutôt que d’écrire
|
1 |
(*pt).a=4; |
on va écrire
|
1 |
pt->a=4; |
cette notation permet d’économiser la frappe de 2 caractères… Oui, rappelez vous, les codeurs sont des fainéants !
Cette notation est très simple mais elle est la source d’un grand nombre d’erreurs chez les étudiants qui maitrisent mal les pointeurs. En effet, il est très facile de confondre. J’ai très souvent la question : « Monsieur, je ne me souviens plus, pour accéder au champs d’une structure, il faut utiliser un point ou une flèche ? »
La réponse est clair nette et précise :
Voici un dernier exemple récapitulant toutes ces notions :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
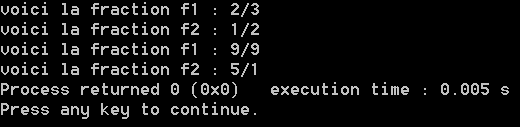
#include<stdio.h> #include<stdlib.h> struct fract { int a;//pour le numérateur int b;//pour le dénominateur }; typedef struct fract fraction; int main (void) { fraction f1={2,3}; fraction f2={1,2}; fraction *pt=NULL; fraction *pt2=NULL; pt =&f1; pt2=&f2; printf("Voici la fraction f1 : %d/%d",f1.a,f1.b); printf("\nVoici la fraction f2 : %d/%d",f2.a,f2.b); (*pt).a=9; (*pt).b=(*pt).a; pt2->a=5; pt2->b=1; printf("\nVoici la fraction f1 : %d/%d",f1.a,f1.b); printf("\nVoici la fraction f2 : %d/%d",f2.a,f2.b); return 0; } |
Et voici l’affichage produit par ce programme :
C’est la fin de ce cours. Tout est clair ? N’hésitez pas a me faire part de toutes vos remarques via les commentaires !!
