Les listes chainées
Sommaire

- Comprendre les pointeurs.
- Savoir définir de nouveaux types de données grâce à struct.
- Être à l’aise avec l’allocation dynamique.
- Comprendre la représentation en mémoire des données.
- Savoir concevoir et manipuler des fonctions récursives.
Commençons par un petit jeu…
Avant, d’expliquer ce que sont les listes et comment les manipuler, nous allons revenir sur un jeu utilisé pour faire visiter les lieux de vacances, les campus ou pour occuper des enfants lors d’un gouter d’anniversaire: la chasse au trésors !
Le principe est simple. Tous les joueurs se rassemblent au point de rendez-vous qui est un lieu connu de tous les participants. L’organisateur distribue un premier indice qui va indiquer (plus ou moins directement) où se trouve l’emplacement où les joueurs doivent se rendre pour découvrir l’indice suivant. Par exemple, « Rendez-vous à l’accueil du centre de vacances ». Les joueurs se rendent donc à l’accueil du centre (dans la joie et la bonne humeur) et découvrent le deuxième indice « rendez vous à la piscine » et ainsi de suite. A chaque étape, un moniteur remet aux joueur une pièce d’un puzzle (ou un morceau de rébus). Lorsque les joueurs arrivent à la dernière étape et reçoivent la dernière pièce du puzzle ils peuvent enfin l’assembler et trouver l’emplacement du trésors, de la récompense. La journée s’achève généralement sur un banquet avec un barde ligoté en haut d’un arbre.
Si vous avez compris comment fonctionne ce jeu, alors vous avez compris comment fonctionnent les listes. Facile, non ? Il ne nous reste qu’a transposer ce mécanisme en langage C :
- On doit savoir où commence la liste (notre point de rendez-vous, par exemple un pointeur vers le premier élément de la liste).
- Une liste est composée d’étapes. Chacune menant à la suivante.
- Chaque étape contient de l’information (la pièce du puzzle, un entier, un tableau…).
- Chaque étape contient l’adresse de l’étape suivante (l’indice menant à l’étape suivante, ou plus concrètement un pointeur vers l’élément suivant).
- On doit pouvoir distinguer le dernier élément.
Mais avant de mettre les mains dans le cambouis, il faut se poser quelques instants et se poser une question toute simple :
Quel est l’intérêt des listes chaînées ?
Dans un tableau, toutes les données sont enregistrées de manière contiguë en mémoire. Cela permet d’accéder directement aux données à partir de leur indice. Mais il y a également certains inconvénients. Par exemple, la mémoire doit contenir un espace suffisamment important pour conserver toutes les données du tableau les unes à coté des autres, ce qui ne peut être garanti si la taille du tableau est importante. De plus, la suppression d’un élément implique le décalage de toutes les valeurs se situant à des indices plus élevés.
Les listes permettent de palier ces inconvénients. Les données vont êtres enregistrées un peu partout en mémoire (morceau par morceau), ce qui rend plus probable de trouver la place nécessaire. En effet, si on note k le nombre de données, l la taille en octets d’une donnée et m (quelques octets) la taille en octets du liens vers la donnée suivante, on se rends compte qu’il est plus simple de trouver k espaces mémoires de (l + m) octets qu’un espace de taille (k x l) octets lorsque k devient grand. Malheureusement, il est également nécessaire d’ajouter à chaque donnée un lien vers la donnée suivante, ce qui représente un surcout d’utilisation mémoire (k x m octets exactement). De plus, si on souhaite supprimer un élément E de notre liste, il suffit (grosso modo) de changer les liens entre les données qui entourent E (celui qui précède E indique que le suivant n’est plus E mais la suivante de E).
Maintenant que vous êtes convaincus de l’intérêt des listes chainées, nous pouvons voir comment faire en C :
Création d’une liste
La première étape consiste à définir une structure permettant d’enregistrer des données (ici un entier), et de nous indiquer où se trouve l’élément suivant, c’est-à-dire un pointeur vers une structure du type que nous sommes en train de définir.

Beaucoup d’étudiants se posent des questions sur la légalité de cette opération. En effet, il peut sembler perturbant d’utiliser un type que nous n’avons pas encore terminé de définir. Mais souvenez vous un peu de la programmation récursive… Ici, c’est le même principe !
Nous pouvons donc produire le code suivant :
|
1 2 3 4 5 6 7 |
struct maillon { int donnee; struct maillon * next; }; typedef struct maillon element; |
A partir de là, nous allons définir une fonction qui, à partir d’une donnée, va nous retourner un maillon. Cette fonction va se charger d’allouer la memoire et d’initialiser les differents champs de notre maillon.
|
1 2 3 4 5 6 7 8 9 10 |
element * creation_maillon(int nb) { element *nouveau; nouveau=(element*)malloc(sizeof(element)); nouveau->donnees=nb; nouveau->next=NULL; return nouveau; } |
Si vous avez bien compris les cours sur les pointeurs et sur l’allocation dynamique, cela ne doit vous poser aucun problème. Faites attention toutefois à bien initialiser le pointeur vers l’élément suivant (le champs next) à NULL. En effet, on doit pouvoir distinguer la fin d’une liste chainée. Le dernier élément ne doit donc pointer sur rien, ce qui est materialisé par la constante NULL. Si on n’initialise pas explicitement le champs next à NULL, il possedera une valeur quelconque (une valeur résiduelle de ce qui se trouvait à cet emplacement mémoire avant l’allocation dynamique), ce qui risque de poser problème plus tard (bug, plantage, segmentation fault…).
En effet, un maillon contient bien des données ainsi qu’un pointeur vers l’élément suivant, qui vaut NULL puisque nous n’avons pas d’autre élément dans notre liste.
Manipulons les listes chaînées
Nous savons désormais fabriquer des listes chaînées contenant un élément. Nous allons maintenant apprendre à manipuler ces listes pour les fusionner, les afficher, ajouter ou supprimer des éléments, les trier etc… Et tout cela en considérant à chaque fois ces opérations de manière itérative et récursive. Car ne l’oublions pas, les listes chaînées étant définies récursivement, la définition de fonctions récursives pourra dans certains cas être salutaire ou tout du moins plus simple a écrire. Concrètement, cela implique que vous soyez à l’aise avec la récursivité sinon vous risquez de souffrir…
Ajout dans une liste
La première opération que nous allons voir est celle de l’insertion d’un élément dans une liste. Cela nous permettra de construire automatiquement des listes de taille importante d’une part, facilitant ainsi le tests des autres fonctions que nous allons écrire par la suite. D’autre part, les mécanismes d’insertion sont à la fois simples a comprendre et à mettre en oeuvre et ils sont parfaitement représentatifs de la manière dont on va pouvoir manipuler les listes chaînées.
Mais insérer un élément dans une liste, cela peut se faire de combien de manières ? En effet, on peut décider de toujours ajouter les éléments au début de la liste, de toujours les insérer à la fin, de les insérer n’importe où aléatoirement, ou bien décider que notre liste doit être triée et donc insérer un nouvel élément de sorte à ce que la liste reste triée….
Nous n’allons pas explorer toutes les possibilités car il y en a trop, mais nous allons en voir différentes qui vous permettrons de vous adapter à toutes les situations.
Insertion en tête
La première méthode consiste à toujours ajouter le nouvel élément au début de la liste. C’est clairement la méthode la plus simple. En effet, il suffit de dire que le nouveau maillon devient la tete, le début de la liste, et qu’il pointe vers l’ancienne tête de liste (ligne 3). Ensuite nous devons retourner la tête de la nouvelle liste (ligne 4).
|
1 2 3 4 5 |
element * ajout_en_tete(element* liste, element *m) { m->next=liste; return m; } |
Remarquez que cela fonctionne même si la liste a laquelle on souhaite ajouter un maillon est vide. En effet, si le paramètre liste vaut NULL, alors en indiquant que le maillon qui va suivre m est le maillon liste (donc NULL) on va effectivement se retrouver avec une liste chaînée qui ne contiendra qu’un élément, m.
Insertion en queue
On peut aussi choisir d’insérer un élément à la fin de la liste. La technique consiste à parcourir la liste jusqu’au dernier élément, puis de faire pointer le dernier élément vers le nouveau maillon que l’on souhaite insérer. Il faut également penser a traiter le cas particulier où la liste à laquelle on souhaite ajouter le maillon est vide. Dans ce cas, on va retourner l’adresse du maillon que l’on souhaite ajouter. Cela signifie que notre fonction peut modifier la tête de la liste. Comme notre fonction peut modifier la tête de la liste, nous devons trouver un moyen pour l’indiquer à la fonction appelante et lui fournir l’adresse de la nouvelle tête. En effet, notre liste chainée ne peut être parcourue que dans une seule direction. Si nous oublions de sauvegarder l’adresse du nouveau « premier élément », nous ne pourrons parcourir notre liste qu’à partir de l’ancien premier élément, qui maintenant se trouve être le deuxième…
Pour pallier ce problème, le plus simple est de toujours retourner la tête de la liste, qu’un changement soit intervenu ou non.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
element * ajoute_en_queue(element *liste, element *m) { element *tete; tete=liste; if(liste==NULL) { return m; } while(liste->next!=NULL) { liste=liste->next; } liste->next=m; return tete; } |
Quelques explications ligne par ligne :
- Ligne 4 : On sauvegarde la tête de la liste
- Lignes 5 à 8 : Si la liste a laquelle on souhaite ajouter le maillon est vide , on retourne l’adresse du nouveau maillon.
- Ligne 9 : A partir d’ici, on sait que la liste chaînée possède au moins un maillon. On va se déplacer dans la liste chaînée jusqu’à ce qu’on arrive au dernier élément. Pour déterminer si le maillon courant est le dernier, il suffit de vérifier que liste->next vaut NULL.
- Ligne 11 : On se déplace vers le maillon suivant. liste est un pointeur vers un maillon. liste->next est aussi un pointeur vers un maillon (le suivant). on fait donc pointer liste vers liste->next, c’est à dire vers le maillon suivant. En effectuant cette opération, on « perd » l’adresse du maillon précédent. C’est pour cette raison que nous avons sauvegardé l’adresse du premier élément de la liste à la ligne 4.
- Ligne 13 : Lorsqu’on arrive ici, on sait qu’on se trouve à la fin de la liste et il ne nous reste plus qu’a faire pointer le dernier maillon vers le maillon qu’on souhaite ajouter.
- Ligne 14 : On retourne la tête de la liste
Nous allons maintenant considérer une version récursive de cette fonction. Il suffit de considérer deux cas : soit la liste à laquelle ont souhaite insérer le nouvel élément est vide (ce sera notre cas de base), et il faut donc retourner l’adresse du nouveau maillon. Exactement comme dans la version itérative. Comme pour la version itérative, cela signifie que notre fonction va devoir retourner l’adresse de la nouvelle liste.
Remarquons le fait suivant : Si nous insérons un élément à la fin d’une liste qui possède au moins un élément, cela revient à insérer cet élément à la fin de la liste qui débute avec l’élément suivant. Chose très simple à faire grâce à un appel récursif !
|
1 2 3 4 5 6 7 8 9 10 |
element * ajoute_en_queue_rec(element *liste, element *m) { if(liste==NULL) { return m; } liste->next=ajoute_en_queue_rec(liste->next,m); return liste; } |
Quelques explications ligne par ligne :
- Ligne 4 à 7 : Si la liste a laquelle on souhaite ajouter le maillon est vide , on retourne l’adresse du nouveau maillon.
- Ligne 8 : On effectue l’appel récursif en insérant l’élément m à la liste qui débute au maillon suivant, c’est à dire à l’adresse l->next. Cet appel récursif est susceptible de modifier la tête de la liste. Il faut donc mettre à jour le champs next de la liste l.
- Ligne 9 : On retourne la tête de la liste.
Parcours d’une liste depuis le début
Maintenant que nous sommes capable de construire des listes chainées en ajoutant des éléments, que ce soit en tête ou en fin de liste, nous allons considérer différentes fonctions pour afficher les différents éléments de la liste. Ce sera l’occasion d’étudier le comportement des appels récursifs, notamment de l’ordre dans lequel sont effectués les appels de fonctions.
Vous l’avez maintenant compris, pour parcourir une liste il faut partir du premier élément et passer au maillon suivant grâce au champs next. Donc, pour afficher iterativement les éléments d’une liste :
|
1 2 3 4 5 6 7 8 |
void affiche_liste(element *liste) { while(liste!=NULL) { printf("%d.",liste->donnees); liste=liste->next; } } |
Rien de neuf par rapport aux fonctions d’insertion. Nous allons juste en profiter pour considérer deux versions récursives qui ne vont pas produire le même résultat à l’affichage. La première version :
|
1 2 3 4 5 6 7 8 |
void affiche_liste_rec1(element *liste) { if(liste!=NULL) { printf("%d.",liste->donnees); affiche_liste_rec1(liste->next); } } |
La seconde version, où on inverse les lignes 5 et 6 :
|
1 2 3 4 5 6 7 8 |
void affiche_liste_rec2(element *liste) { if(liste!=NULL) { affiche_liste_rec2(liste->next); printf("%d.",liste->donnees); } } |
Dans la première version, nous affichons la valeur du maillon courant PUIS nous effectuons l’appel récursif.
Dans la seconde version, nous effectuons l’appel recursif PUIS nous affichons la valeur du maillon courant. Ainsi, la valeur du maillon courant n’est affichée que lorsque les appels récursifs sont termines, ce qui va complètement changer le résultat. Par exemple, si notre liste contient les entiers de 0 à 9, dans l’ordre, avec 0 en tête, la valeur 0 ne sera affichée que lorsque le reste de la liste sera affiché.
(Reste de la liste)0.
((Reste de la liste)1)0.
(((Reste de la liste)2)1)0.
Etc..
Voici un exemple qui va nous permettre de visualiser le comportement de nos trois fonctions d’affichage :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
int main() { int i; element *tete=NULL; for(i=0; i<10; i++) { tete=ajoute_en_queue_rec(tete,creation_maillon(i)); } printf("\nAffichage avec la fonction iterative :"); affiche_liste(tete); printf("\nAffichage avec la fonction recursive 1 :"); affiche_liste_rec1(tete); printf("\nAffichage avec la fonction recursive 2 :"); affiche_liste_rec2(tete); return 0; } |
Ce programme va produire le résultat suivant :

Recherche d’un élément dans une liste
Nous savons créer des listes chaînées, et les parcourir pour afficher les différentes valeurs présentes. Donc vous devez être capable de produire une fonction qui va tester si une valeur est présente dans une liste. En effet, il faut parcourir la liste et tester pour chaque maillon si la valeur contenue est celle recherchée. On pourrait retourner 1 ou 0 pour dire si l’élément est présent ou non dans la liste, mais si on retourne l’adresse du maillon contenant la valeur recherchée nous allons gagner en expressivité. Non seulement on aura l’information voulue (la valeur est présente ou non) mais en plus on saura où elle se trouve. Bien sur, si la valeur recherchée n’est pas présente dans la liste nous allons retourner …. NULL…
Voici une version itérative :
|
1 2 3 4 5 6 7 8 9 10 11 12 |
element * recherche(element *liste,int valeur) { while(liste!=NULL) { if(liste->donnees==valeur) { return liste; } liste=liste->next; } return NULL; } |
Et voici une version récursive :
|
1 2 3 4 5 6 |
element *recherche_rec(element *liste, int valeur) { if(liste==NULL) return NULL; if(liste->donnees==valeur) return liste; return recherche_rec(liste->next,valeur); } |
Un petit programme pour tester nos fonctions :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
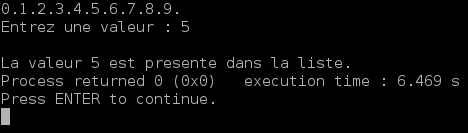
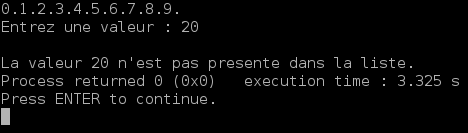
int main() { int i,nb; element *tete=NULL; for(i=0; i<10; i++) { tete=ajoute_en_queue_rec(tete,creation_maillon(i)); } affiche_liste(tete); printf("\nEntrez une valeur : "); scanf("%d",&nb); if(recherche_rec(tete,nb)==NULL) { printf("\nLa valeur %d n'est pas presente dans la liste.",nb); } else { printf("\nLa valeur %d est presente dans la liste.",nb); } return 0; } |
Voici deux résultats possibles, suivant que la valeur recherchée est présente ou non dans la liste :
Lorsque la valeur est présente dans la liste :
Lorsque la valeur n’est pas présente dans la liste :
Suppression dans une liste
Si vous arrivez jusqu’ici, c’est que vous savez manipuler les listes chaînées, du moins les opérations les plus simples. Il ne nous reste plus qu’a supprimer des éléments (ça peut être utile…) et a libérer la mémoire réservée pour la liste. Cette dernière opération est essentielle si on veut éviter une fuite de mémoire.
libérer la mémoire allouée à une liste chaînée
Lorsque l’on libère la mémoire utilisée par une liste chainée, il faut faire attention à ne pas tenter d’accéder aux données d’un maillon déjà libéré. En effet, plus rien ne peut garantir que les données correspondent à celle que vous aviez avant la libération du maillon. Cela implique que si vous libérez la mémoire du premier maillon, vous devez auparavant sauvegarder l’adresse du maillon suivant !
|
1 2 3 4 5 6 7 8 9 10 |
void liberer(element *liste) { élément *tmp ; while(liste!=NULL) { tmp=liste->next; free (liste); liste=tmp; } } |
Plusieurs versions récursives sont également possible. Comme pour la fonction d’affichage, il est possible de jouer sur l’ordre des opérations et des appels. La première version va libérer la mémoire en partant du premier maillon. La seconde, bien que partant du premier maillon, va libérer la mémoire en partant du dernier maillon (par le jeu des appels récursifs qui s’exécutent AVANT l’instruction free), ce qui nous évite d’avoir à sauvegarder l’adresse du prochain maillon à libérer.
|
1 2 3 4 5 6 7 8 9 10 |
void liberer(element *liste) { élément *tmp ; if(liste!=NULL) { tmp=liste->next; free (liste); libérer(tmp); } } |
la seconde version :
|
1 2 3 4 5 6 7 8 |
void liberer(element *liste) { if(liste!=NULL) { liberer(liste->next); free (liste); } } |
Suppression du premier élément
Supprimer le premier maillon ne doit poser aucun problème ! On sauvegarde l’adresse du maillon suivant, on libère le premier maillon et on retourne l’adresse du deuxième maillon, qui correspond à notre nouvelle tête de liste :
|
1 2 3 4 5 6 7 8 9 10 11 |
element * suppression_tete(element *liste) { element *tmp; if(liste!=NULL) { tmp=liste->next; free (liste); return tmp; } return NULL; } |
suppression du dernier élément
Suppression d’un élément quelconque
